Diese Lektion erläutert Schritt-für-Schritt wie ein PHP-Skript mit einer Datenbank verbindet. Dies ist ein erforderlicher Schritt, um Daten mittels PHP aus einer Datenbank auszulesen. WordPress wäre sonst nicht in der Lage, den Content deines Posts auszulesen und würde nur ein leeres Theme an den Nutzer zurück geben.
Wir bauen hier eine Brücke von Theme zu Content, von PHP zu MySQL.
Benötigte Funktionen in PHP zur Interaktion mit MySQL-Servern
Wenn Du Content aus einer Datenbank auslesen möchtest, benötigst Du mindestens die folgenden Funktionen:
- mysqli_connect($db_server, $db_user, $db_password, $db_name) — öffnet eine Verbindung zu einem Datenbank-Server (gibt $db_connection zurück)
- mysqli_query($db_connection, $sql_query_string) — sendet ein SQL-Statement an das DBS (gibt $statement zurück)
- mysqli_fetch_row($statement) — erzeugt ein Result-Set mit den Antwort-Daten der SQL-Anfrage (gibt $result zurück)
- mysqli_insert_id($db_connection) — gibt die zuletzt generierte ID zurück, die durch auto_increment vom DBS vergeben wurde (gibt $last_id zurück)
- mysqli_error() — gibt den Fehler als String zurück, der vom DBS im Falle eines Fehlers erzeugt wure (gibt $fehlermeldung zurück)
- mysqli_num_fields($statement) — gibt die Anzahl von Spalten im aktuellen Statement zurück
Es gibt nun verschiedene Szenarien des Auslesens von Daten, die wir uns anschauen wollen.
Datenbankverbindung und simples Daten-Auslesen
Der folgende Quellcode ist ein Beispiel für einen vollständigen PHP-Datenbank-Roundtrip:
1 2 3 4 5 6 7 | <?php $server = "dbs.your-domain.com"; $user = "bob"; $password = "P4ssW0rD!"; $database = "wordpress"; $conn = mysqli_connect($server, $user, $password, $database); ?> |
Der oben aufgeführte Quellcode befähigt dich zwar zum Aufbau einer Datenbankverbindung ausgehend von deinem PHP-Skript. Doch bislang haben wir noch keine Daten erhalten.
1 2 3 4 5 | <?php $stmt = mysqli_query($conn, "SELECT TEXT FROM TEST") or die ( mysql_error() ); $row = mysqli_fetch_row($stmt); echo $row[0]; // gives the first item of TEXT in TEST ?> |
Die letzten zwei Zeilen erlauben das Auslesen von Daten — jedoch nur für die erste Zeile (den ersten Datensatz) und den ersten darin befindlichen Attribut-Wert.
Ein Attribut und alle Zeilen mit Hilfe einer WHILE-Schleife lesen
Wenn Du alle Zeilen einer Tabelle TEST für das Attribut TEXT auslesen möchtest, müsstest Du eine WHILE-Schleife verwenden:
1 2 3 4 5 6 | <?php $stmt = mysqli_query($conn, "SELECT TEXT FROM TEST") or die ( mysql_error() ); while ($row = mysqli_fetch_row($stmt)) { echo $row[0]; // gibt aktuellen Wert von TEXT in TEST } ?> |
Diese WHILE-Schleife befähigt dich zur Ausgabe aller Werte des Attributes TEXT in TEST.
Viele Attribute und alle Zeilen mit Hilfe von WHILE- und FOR-Schleifen lesen
Wenn Du alle Zeilen der Tabelle TEST für mehr als ein Attribut auslesen möchtest, geht dies folgendermaßen:
1 2 3 4 5 6 7 8 9 | <?php $stmt = mysqli_query($conn, "SELECT ID, TEXT FROM TEST") or die ( mysql_error() ); $column_count = mysqli_num_fields($stmt); while ($row = mysqli_fetch_row($stmt)) { for ($j = 0; $j < $column_count; $j++) { echo $row[$j]; // gibt aktuellen Spalten-Wert von TEST } } ?> |
Du siehst hier, dass wir eine FOR-Schleife in die WHILE-Schleife gesetzt haben. Diese FOR-Schleife zählt durch jedes Attribut (Spalte) einer Tabelle, während die WHILE-Schleife außerhalb weiterhin jede Zeile ausliest.
Der Vorteil dieses Quellcodes ist, dass Du ihn für jede Tabelle und jedes Attribut wiederverwenden kannst.
Diese Lektion ist fundamental wichtig für die Verknüpfung zwischen PHP und MySQL. In den nächsten Lektionen werden wir nun alltägliches Daten-Auslesen behandeln — zunächst demonstriert an einem praktischen Beispiel: einem Login-Skript in PHP, welches Benutzerdaten aus einer MySQL-Datenbank ausliest.
Die nächsten Lektionen:
Diese Lektion gibt dir eine Schritt-für-Schritt-Anleitung zur Entwicklung eines Login-Skriptes mit PHP und MySQL. Du erhältst ein grundlegendes Verständnis darüber, wie ein Content Management System wie WordPress mit einer Datenbank kommuniziert, Daten ausliest und diese weiter verarbeitet, um finalen HTML-Code an den Browser des Benutzers zu übergeben.
Datenbank-Vorbereitungen für Nutzer-Verwaltung
Zunächst benötigen wir eine Datenbank-Tabelle mit unseren Login-Informationen als Referenz für spätere Login-Prüfungen. Wir können folgende Tabelle nutzen:
1 2 3 4 5 | create table user ( id int(20) primary key auto_increment, username varchar(120) unique, password varchar(120) ) |
Das Attribut “id” dient der performanten Verarbeitung bei Sortierung und Verarbeitung unserer Nutzer-Informationen. Es ist unser Primärschlüssel und wird automatisch durch das DBMS herauf gezählt wenn eine neue Zeile (ein neuer Datensatz) hinzugefügt wird.
Das nächste Attribut “username” ist eine Text-Spalte mit unserem eindeutigen Nutzernamen.
Das letzte Attribut “password” ist ebenfalls eine Text-Spalte, welche das Kennwort eines jeden Nutzers trägt und nicht eindeutig sein muss. Wir werden dieses Attribut nicht im Klartext setzen sondern mit einem Hash-Wert füllen, doch das erst später per PHP.
Für den Anfang wird diese Tabelle unsere Login-Informationen halten. Wir befüllen sie mit einigen Nutzerdaten:
1 2 3 | insert into user values (null, 'bob', 'secret'); insert into user values (null, 'paul', 'god'); insert into user values (null, 'sandra', 'flower'); |
Wir verwenden hier zunächst Kennwörter im Klartext, um es einfacher zu machen zu verstehen, wie unser Login-Skript funktioniert. Wir werden später noch einen sichereren Weg zur Speicherung der Passwort-Informationen aufzeigen.
Entwicklung einer HTML-User-Login-Oberfläche
Wie in der Lektion zu HTML-Formelementen erläutert werden wir ein Login-Formular konstruieren, welches POST-Parameter verarbeitet. Wir können den folgenden Code verwenden, den wir in eine Datei “login-form.html” setzen:
1 2 3 4 5 6 7 8 9 | <html><head><title>Login form</title></head> <body> <form action="user-login-processing.php" method="POST" enctype="text/plain"> Username: <input type="text" name="username" value="" /><br /> Password: <input type="password" name="password" value="" /><br /> <button type="submit" value="Login">Login</button> </form> </body> </html> |
Das ist alles was wir für ein grundlegendes HTML-Login-Formular benötigen. Der Nutzer wird nach seinem Benutzernamen und Kennwort gefragt. Klickt er dann auf den Login-Button, werden die Formular-Inhalte an das PHP-Skript “user-login-processing.php” übergeben und dort weiter verarbeitet.
Mit unserer Datenbank verbinden
Lass uns nun schauen was unser Skript “user-login-processing.php” tun muss.
Wie in diesem Artikel erläutert müssen wir zunächst mit unserer Datenbank verbinden. Das tun wir wie folgt:
1 2 3 4 5 6 7 8 | <?php $server = "dbs.your-domain.com"; $user = "bob"; $password = "P4ssW0rD!"; $database = "wordpress"; mysql_connect($server, $user, $password); mysql_select_db($database); ?> |
Sobald wir verbunden sind, können wir unsere Parameter verarbeiten.
User-Input gegen Datenbank-Inhalte prüfen
Als erstes greifen wir die Werte unserer Parameter ab:
1 2 3 4 | <?php $username = @$_POST["username"]; $password = @$_POST["password"]; ?> |
Der oben aufgeführte Quellcode speichert die Werte unserer Nutzer-Eingaben in Variablen, die den selben Namen tragen wie unsere Parameter. Das macht es so einfach und überschaubar wie möglich. Das @-Zeichen weist das PHP-Skript an, fehlende Werte nicht mit einem Ausgabe-Fehler zu versehen.
Sobald wir sowohl verbunden sind als auch unsere Parameter-Werte abgegriffen haben, können wir unsere Datenbank befragen, ob ein Nutzer mit der im Login-Formular eingegebenen Benutzername-Passwort-Kombination existiert.
Was im unten ersichtlichen Quellcode passiert wird in dieser Lektion beschrieben. Das wichtige an dieser Stelle ist, dass wir die Datenbank befragen, ob zwei spezifische Bedingungen in einem Datensatz gegeben sind: sowohl Nutzer-Name als auch Passwort müssen in der Datenbank vorhanden sein.
Da unser Nutzer-Name eindeutig ist, kann es keinen zweiten Datensatz geben, der für den Vergleich in Frage kommt. Es kann jedoch sein, dass es gar keinen Datensatz gibt, sobald entweder Nutzer-Name oder Passwort (oder beides) falsch sind.
1 2 3 4 5 6 7 8 9 | <?php $sql="select id from user where username = '$username' and password = '$password'"; $stmt = mysql_query($sql) or die ( mysql_error() ); //$row = mysql_fetch_row($stmt); //if we wanted to test our statement //echo $row[0]; //if we wanted to test our statement $num_rows = mysql_num_rows($stmt); if ($num_rows == 1) { echo "You are logged in"; } else { header('Location: login-form.html'); } ?> |
Das Attribut das tatsächlich in der Datenbank ausgewählt wird ist in unserem Fall ID. Das ist an dieser Stelle irrelevant und dient lediglich dem Zweck, ein Ergebnis zu haben, falls eine über Einstimmung gefunden wurde.
Falls es solch eine Übereinstimmung gibt, sehen wir “You are logged in”. Wenn es keine gibt, leitet das Skript zurück zum Login Formular.
Das komplette Login-Skript in Kürze
Dies ist die vollständige Version des oben erläuterten Quellcodes.
Das HTML-Login-Formular “login-form.html”:
1 2 3 4 5 6 7 8 9 | <html><head><title>Login form</title></head> <body> <form action="user-login-processing.php" method="POST" enctype="text/plain"> Username: <input type="text" name="username" value="" /><br /> Password: <input type="password" name="password" value="" /><br /> <button type="submit" value="Login">Login</button> </form> </body> </html> |
Das PHP-Ziel-Skript “user-login-processing.php” das für das Login verwendet wird:
<?php // parameter grabbing $username = @$_POST["username"]; $password = @$_POST["password"]; // database connection $server = "dbs.your-domain.com"; $user = "bob"; $password = "P4ssW0rD!"; $database = "wordpress"; mysql_connect($server, $user, $password); mysql_select_db($database); // initiate login procedure $sql="select id from user where username = '$username' and password = '$password'"; $stmt = mysql_query($sql) or die ( mysql_error() ); //$row = mysql_fetch_row($stmt); //if we wanted to test our statement //echo $row[0]; //if we wanted to test our statement $num_rows = mysql_num_rows($stmt); // login successfull? if ($num_rows == 1) { echo "You are logged in"; // do your stuff } else { header('Location: login-form.html'); } ?> |
Ein gutes Video-Tutorial, welches den selben Inhalt behandelt wie diese Lektion (jedoch mit etwas abweichendem Quellcode), findest Du hier:
https://www.youtube.com/watch?v=5XpBzLVHkPY
Gedanken in Richtung Informationssicherheit
Der oben aufgeführte Quellcode ist nicht sonderlich sicher. Du möchtest SQL-Injection und andere Manipulationsversuche abfangen, was hier jedoch zu weit führt.
Verwende jedoch zumindest die folgende Prozedur, um deine Kennwörter nicht im Klartext in der Datenbank zu speichern. Der folgende Code produziert eine gehashte Version von “asdf” als mögliches (unsicheres) Passwort.
1 2 3 | <?php echo sha1("asdf"); ?> |
Du kannst sha1($password) innerhalb des Quellcodes weiter oben nutzen, um die Passwort-Eingabe eines Nutzers zu hashen, gleich nachdem sie als Parameter-Wert abgegriffen und kurz bevor sie an die Datenbank gesendet wurde. Diese Prozedur wird in die selbe Antwort münden – entweder ist eine solche Nutzer-Name/Passwort-Kombination vorhanden oder nicht.
Das erfordert jedoch, dass Du deine Kennwörter auch gehasht in der Datenbank vorhältst (da sonst selbst bei korrekter Nutzereingabe keine Übereinstimmung zustande kommen kann). Du kannst “echo sha1(‘meinKennwort’)” nutzen, um deinen gewünschten Hash-Wert einzusehen.
Auch möchtest Du vielleicht deine Parameter escapen etc. – schau dir für etwas mehr Sicherheit daher gern das Video weiter oben an.
WordPress-Implikationen
Auch wenn wir ein übliches Problem verwenden, um das Auslesen von Daten aus der Datenbank zu demonstrieren: die grundlegende Lektion, die Du verstehen darfst ist folgende.
Zunächst muss dein PHP-Skript eine Verbindung zur Datenbank aufbauen. Dann verwendest Du diese Verbindung, um die Datenbank nach bestimmten Informationen zu fragen. Schließlich verwendest Du diese Daten, um bestimmte Aktionen durchzuführen, beispielsweise die Weiterleitung des Nutzers – wie in unserem Login-Beispiel.
Dieser Roundtrip ist das, worüber wir zu Beginn dieses Tutorials sprachen. Was jetzt noch fehlt, um einen kompletten Nutzer-Anfragezyklus zu komplettieren, ist das Ergebnis als HTML zurückzugeben, welches der Browser des Nutzers verstehen kann. Auch möchtest Du dabei berücksichtigen, dass Daten in der Datenbank geändert werden können. Diesen Themen widmen wir uns in der letzten Lektion.
Die nächste Lektion:
Diese Lektion gibt eine Schritt-für-Schritt-Anleitung darüber, wie Du Daten aus einer MySQL-Datenbank auslesen und den Inhalt anschließend mittels Tabellen visualisieren und via Formular editieren kannst. Dies bringt alle Schritte vorheriger Lektionen zusammen. Es ist auch das, was WordPress tut, um den vollständigen Zyklus einer Nutzer-Interaktion mit dem CMS abzubilden – von der Anfrage von Daten bis zur visuellen Ausgabe des angefragten Ergebnisses.
Unsere Datenverwaltungs-Ausgabe
Als Beispiel wollen wir eine Comic-Verwaltung als Datenbank-Anwendung entwickeln, welche Daten wie folgt verwaltet:

Wenn ein Nutzer “Delete” anwählt, wird der Eintrag aus der Datenbank entfernt.
Klickt er auf “Edit” wird folgendes Formular ausgegeben:
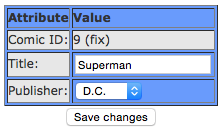
Schließlich erhält ein Nutzer nach Klick auf “Create new comic” folgendes Formular angezeigt:
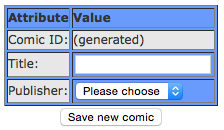
Diese Lektion wird alle für diese Mechanik erforderlichen Schritte technisch erläutern. Style-Angaben seien dabei außen vor.
Datenbank-Vorbereitungen
Lass uns zunächst über die Datenbank-Tabellen sprechen, die wir benötigen.
Datenbanktabelle COMIC
Die Eigenschaften “ID” und “Comic_Name” sind direkte Attribute der Tabelle “Comic”. Der Verlag-Verweis “Publisher_ID” ist ein Fremdschlüssel einer weiteren Tabelle, genannt “Publisher”.
| ID | Comic_Name | Publisher_ID |
|---|---|---|
| 7 | The Incredible Hulk | 0 |
| 9 | Superman | 1 |
Datenbanktabelle PUBLISHER
Die Tabelle “Publisher” wird wie folgt aussehen:
| ID | Publisher_Name |
|---|---|
| 0 | Marvel |
| 1 | D.C. |
Sprechen wir nun darüber, was mit diesen Tabellen geschehen soll.
MySQL-Daten mit PHP auslesen
Wie in diesem Tutorial bereits besprochen, verbinden wir zur Datenbank und verwenden nun den folgenden Code, um Daten aus MySQL zu lesen. Dabei nutzen wir eine WHILE-Schleife innerhalb einer Datei mit dem fiktiven Namen content-start.php, welche von Header und Footer umgeben ist, wie bereits erläutert:
<?php echo "<table>"; $stmt = mysql_query("SELECT ID, Comic_Name, Publisher_Name from COMIC, PUBLISHER where COMIC.Publisher_ID = PUBLISHER.ID order by COMIC.Title"); while ($row = mysql_fetch_row($stmt)) { echo "<tr>"; for ($j = 0; $j < 3; $j++) { // we're expecting three attributes echo "<td>".$row[$j]."</td>"; // gives the current item of the current attribute } echo " <td><a href="index.php?section=comic&function=edit&id=$row[0]">Edit</a></td>"; echo " <td><a href="index.php?section=comic&function=delete&id=$row[0]">Delete</a></td>"; echo "</tr>"; } echo "<table>"; echo "<a href="index.php?section=comic&function=new">Create new comic</a>"; ?> |
Es gibt hier jedoch einige Neuerungen:
- Wir geben nicht länger nur einfache Datenbank-Informationen aus, sondern nutzen HTML-Tabellen zur Ausgabe. Diese Ausgabe wird generiert von PHP durch Definition einer HTML-Tabelle außerhalb der WHILE-Schleife, einer Zeile innerhalb der WHILE-Schleife und einer Spalte innerhalb eines FOR-Schleifen-Zyklus.
- Wir verbinden zwei Datenbank-Tabellen miteinander unter Verwendung von SQL-Statements.
- Wir erweitern die Attribut-Spalten mit zwei zusätzlichen Spalten, die unsere HTML-Links tragen, die zu mehr Funktionen führen.
MySQL-Daten mittels PHP löschen
Klickt ein Nutzer auf “Delete” müssen wir ein Delete-Statement an die Datenbank senden.
Der erste Schritt ist bereits getan. Schauen wir uns den Quellcode oben oben, sehen wir einen Link mit dem Ankertext “Delete”, der bereits die ID jedes Comics mitführt. Getan werden müssen noch folgende Schritte:
- Die transportierte ID abgreifen
- Das korrekte Statement an die Datenbank formulieren und absenden
- Den Nutzer zur vorherigen Seite zurück führen
Da der Link lautet “index.php?section=comic&function=delete&id=$row[0]” müssen wir als erstes schauen wo wir sind. Wir gehen hier weiterhin vom Navigationsrahmen aus, wie vorher erläutert. Falls Du dessen Aufbau verstanden hast, ist das Problem der Nutzer-Umleitung bereits erledigt. Er wird hier beispielsweise zu einer Datei content-comic.php umgeleitet, die in den übergeordneten Rahmen eingebettet ist.
Innerhalb dieser Datei müssen wir einen zusätzlichen Parameter “function” auslesen, denn wir wollen unterscheiden zwischen Erzeugen, Ändern und Löschen von Comics. Auch müssen wir die übergebene ID abgreifen. Beides erledigen wir wie im Beitrag zu GET- und POST-Parametern beschrieben:
<?php $function = $_GET["function"]; $comic_id = $_GET["id"]; if ($function == "delete") { $sql = "delete from COMIC where ID = $comic_id"; mysql_query($sql); header('Location: index.php?section=comic'); } ?> |
Das war der einfache Teil.
MySQL-Daten mittels PHP editieren
Nun wird es etwas komplexer. Wir können zwar den selben Mechanismus wie oben beschrieben nutzen, um die Funktion “edit” abzugreifen, müssen allerdings etwas mehr tun, um dem Nutzer die Möglichkeit zu geben, die Informationen zu verändern.
Zunächst möchte ein Nutzer die gegenwärtige Information sehen, da dies eine Erleichterung darstellt, sie zu ändern. Deshalb wählen wir alle Informationen aus, die zur aktuellen Comic-ID gehören.
Anschließend geben wir diese Information über folgende Wege aus:
- Als reiner Text ohne Textfeld (wie die ID, unveränderbar)
- Innerhalb eines Textfeldes (wie der Comic-Titel)
- Innerhalb eines Dropdown-Menüs (wie der Comic-Publisher, mit Vor-Auswahl des aktuellen Publishers)
Zusätzlich ist die aktuelle Comic-ID in einem versteckten Feld enthalten, um sie per Formular übergeben zu können, wovon der Nutzer nichts mitbekommt.
Studiere nun bitte den folgenden Quellcode, der all dies erledigt:
<?php $function = $_GET["function"]; $comic_id = $_GET["id"]; if ($function == "edit") { echo "<form action='index.php?section=comic&function=edited' method='POST'>"; echo "<table>"; $stmt = mysql_query("select ID, Comic_Name, Publisher_ID, Publisher_Name from COMIC, PUBLISHER where COMIC.Publisher_ID = PUBLISHER.ID and COMIC.ID = $comid_id"); while ($row = mysql_fetch_row($stmt)) { echo "<tr>"; echo " <td>ID</td>"; echo " <td>".$row[0]."</td>"; // not changeable echo "</tr>"; echo "<tr>"; echo " <td>Title</td>"; echo " <td><input type='text' name='edited_comic_title' value='".$row[1]."'/></td>"; // changeable echo "</tr>"; echo "<tr>"; echo " <td>Publisher:</td>"; echo " <td><select name='edited_publisher_id' type='text' value=''/> <option value='$row[2]'>$row[3]</option>"; $sql = "select ID, Publisher_Name from PUBLISHER where ID not like $row[2] order by ID asc"; $stmt_inner = mysql_query($sql); $i = 0; while ($row_inner = mysql_fetch_row($stmt_inner)) { $j = 0; $ID_Publisher[$i] = $row[$j]; $j++; $Title_Publisher[$i] = $row[$j]; echo " <option value='$ID_Publisher[$i]'>$Title_Publisher[$i]</option>"; $i++; } echo " <td>"; echo "</tr>"; } echo "</table>"; echo "<input name='comic_id' value='$comic_id' type='hidden'/>"; echo "<input name='Save' value='Save' type='submit'/>"; echo "</form>"; } if ($function == "edited") { $edited_comic_title = $_POST["edited_comic_title"]; $edited_publisher_id = $_POST["edited_publisher_id"]; $comic_id = $_POST["comic_id"]; $sql = "update COMIC set Comic_Name = '$edited_comic_title', Publisher_ID = $edited_publisher_id where ID = $comic_id"; mysql_query($sql); header('Location: index.php?section=comic'); } ?> |
Du siehst, es findet hier ein Vergleich zwischen der Variable “function” und dem String “edited” statt. Die Variable function trägt diesen String wenn das Formular abgesendet wird, welches alle vorherigen Input-Felder enthielt. Alle POST-Parameter werden bezogen über ein SQL-Update-Statement, das zur Datenbank gesendet wird. Der Nutzer wird dann zu seinem Ausgangspunkt zurück geleitet.
Neue MySQL-Daten mit PHP erzeugen
Glücklicherweise kannst Du den selben Quellcode wie oben nutzen, um neue Comics in die Datenbank einzufügen. Behalte jedoch im Hinterkopf, dass es keine Vorauswahlen und keine aktuellen Werte in der Ausgabe gibt. Insbesondere wirst Du nicht die aktuelle ID des Comics ausgeben können, da noch keine existiert. Die neue ID wird generiert, sobald Du dein Insert-Statement an die Datenbank sendest:
<?php $function = $_GET["function"]; $comic_id = $_GET["id"]; if ($function == "new") { // see above ... } if ($function == "new_done") { $new_comic_title = $_POST["new_comic_title"]; $new_publisher_id = $_POST["new_publisher_id"]; $comic_id = $_POST["comic_id"]; $sql = "insert into COMIC values (null, '$new_comic_title', $new_publisher_id)"; mysql_query($sql); header('Location: index.php?section=comic'); } ?> |
In Ordnung. Das ist alles was eine Datenbank-Anwendung tun muss: lesen, löschen, aktualisieren und einfügen von Daten in eine Datenbank. Hierbei finden HTML und PHP Verwendung, um sowohl die Nutzereingaben zu verarbeiten, als auch Formular- und weitere visuelle Ausgaben zu formulieren, die ein Browser verstehen kann. Es ist tatsächlich relativ einfach, auch wenn deine WordPress-Themes und -Plugins diese Funktionalität komplex ausweiten. Doch die Grundstruktur ist wenig kompliziert.
Was bedeutet all dies für dich als Blogger?
WordPress ist eine große Datenbank-Anwendung. Geschrieben in PHP ist es in der Lage zu einer MySQL-Datenbank zu verbinden und mit ihr zu kommunizieren. Die erhaltenen Daten kann WordPress verarbeiten und dem Benutzer eine sauber aufbereitete HTML-Webseite zurück liefern, die ein Browser interpretieren und darstellen kann. WordPress kennt dabei zwei Typen von Nutzer: Fronten User und Backend User. Diese haben jeweils andere Rollen und Privilegien, doch der Mechanismus zur Handhabung von Datei-Eingaben, ihre Verarbeitung Auslieferung in Form einer HTML-basierten Antwort ist stets identisch.
Wir hoffen Du hast einen Einblick in die Funktionsweise deiner Blogging Software WordPress erhalten. Vielleicht möchtest Du künftig bestimmte Probleme deines Themes selbst lösen. Solltest Du darüber hinaus Hilfe mit deiner Installation benötigen, kannst Du dich gern melden.
Du hast es geschafft. Springe jetzt gern in jede Lektion direkt zurück, falls Du noch Verständnisprobleme hast. Auch kannst Du uns bei offenen Fragen gern kontaktieren.
Viel Erfolg! 🙂
Diese Lektion nimmt dich bei der Hand und zeigt, welche clientseitigen und serverseitigen Komponenten Du benötigst und welche Möglichkeiten es gibt, um eine datenbankgestützte Webanwendung erfolgreich zu erstellen. Wir werden auch darauf hinweisen, was WordPress bereits anspricht und wie der Inhalt dieser Lektion Ihnen helfen kann, Probleme mit Ihrem Blog zu lösen.
Die allgemeine Architektur
Schauen wir uns zunächst die Gesamtarchitektur an, mit der wir uns bei der Entwicklung befassen:
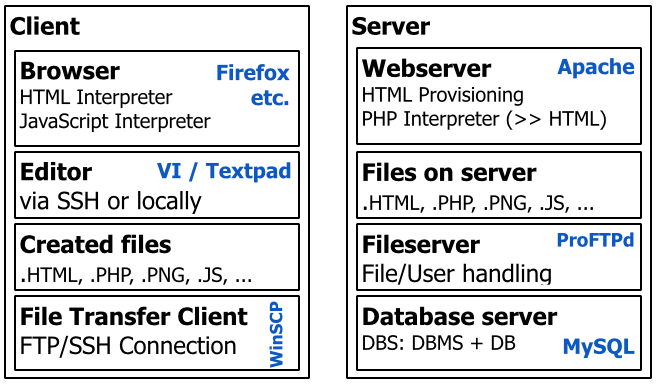
Unser Kunde stellt uns einen Webbrowser zur Verfügung, der HTML- und bei Bedarf JavaScript-Skripte interpretieren kann. All dies erfolgt auf der Clientseite ohne Serverinteraktion nach dem ersten Empfang der betreffenden Dateien.
Dann haben wir noch auf unserem Client entweder einen Editor zum lokalen Erstellen unserer Dateien oder eine Terminalanwendung, mit der wir Code aus der Ferne entwickeln können. Ich werde dies gleich behandeln.
Wir haben bereits die Dateien erwähnt, die lokal erstellt werden können oder müssen, z. HTML-Markup, PHP-Code, JavaScript-Code oder Bilder (JPG, PNG usw.). Alle Dateien, die wir lokal (auf der Clientseite) erstellen, müssen auf den Server übertragen werden, wo sie in den Webbrowsern anderer Personen bereitgestellt werden können.
Diese Übertragung von unserem Entwickler-Client auf den Server erfolgt mithilfe von Client-Tools für die Dateiübertragung wie WinSCP (Windows) oder Cyberduck (OSX). Sie unterstützen verschiedene Protokolle wie FTP oder SSH, abhängig von Ihrer bevorzugten Kommunikationsmethode und den Fähigkeiten Ihres Servers.
Lass uns nun einen Blick darauf werfen, wie deine Entwicklung stattfinden kann.
Der Client-zentrierte Entwicklungsansatz
Es gibt verschiedene Möglichkeiten, sich zu entwickeln. Ein Weg ist zugunsten des Kunden. Du kannst eine lokale Editoranwendung auf deinem Desktop verwenden, um alle Arten von Code zu erstellen, zum Beispiel Textpad. Du musst deinen Quellcode dann mit deinem Dateiübertragungsclient auf den Server übertragen, zum Beispiel mit WinSCP.
Diese Anwendung kontaktiert dann den Dateidienst auf dem Server, an den Du Dateien senden möchtest. Dort wird möglicherweise ein ProFTPd ausgeführt (das Gegenstück zu deinem Dateiübertragungsclient, das für dich nicht interessant ist, es sei denn, Du möchtest deinen eigenen Dateiserver einrichten).

Dieser Dateiserver legt dann alle empfangenen Dateien auf der Hardware des Servers ab, auf die beispielsweise der Webserver zugreifen kann – was wir wollen, nicht wahr 🙂
Der Server-zentrierte Entwicklungsansatz
Eine andere Entwicklungsmethode ist zugunsten des Servers. Du kannst eine clientseitige Anwendung wie Putty (Windows) oder Terminal (OSX) verwenden, um über SSH eine Verbindung zu deinem Server herzustellen. Sobald die Verbindung hergestellt ist, kannst Du serverseitige Bearbeitungstools wie VI verwenden. Wir werden die VI-Behandlung in einer späteren Lektion erläutern.

Der Vorteil hierbei ist, dass Du keinen Code auf den Server übertragen musst, da Du Dateien direkt auf die Festplatte des Servers schreibst.
Der Nachteil ist, dass Du ständig eine stabile Internetverbindung aufrechterhalten musst, was in überfüllten WLAN-Umgebungen schwierig sein kann.
Der Client-Server-Roundtrip
Nun wollen wir sehen, was passiert, wenn Du oder ein anderer Benutzer versucht, auf von dir erstellte Dateien zuzugreifen. Der Browser sendet eine Anfrage für eine bestimmte Datei. Dies ist auch der Fall, wenn auf die Adresse, auf die zugegriffen wird, nur “www.domain.com” lautet, da der Webserver, der diese Anfrage empfängt, nach einer Datei mit dem Namen index.php oder index.html sucht . Sobald diese Datei gefunden wurde, hängt das nächste Vorgehen von der Art der Datei ab, auf die zugegriffen wird.

HTML-Bereitstellung
Wenn es sich bei der fraglichen Datei um reines HTML oder einfaches JavaScript handelt, sendet der Server das Markup einfach an den Browser zurück, wo es interpretiert werden kann.
Server-seitige Skript-Interpretation
Wenn die Datei PHP oder eine andere serverseitige Skriptsprache enthält, müssen auf dem Webserver Interpreter-Module installiert sein, mit denen das Skript weiter verarbeitet werden kann. Jede Skriptverarbeitung führt zu einer weiteren Markup-Ausgabe (z. B. HTML), die nach der Übertragung vom Browser des Clients interpretiert werden kann. Die Art und Weise, wie dieses Markup erstellt wurde, ist jedoch für die Außenwelt nicht sichtbar.
Server-seitige Skript- und Datenbank-Interaktion
Mit einem PHP oder einem anderen serverseitigen Skript kann eine Datenbank auch eine Rolle beim Zugriff auf strukturierte Daten spielen, z. B. beim Verarbeiten von Anmeldeinformationen. Der Webserver benötigt dann weitere Komponenten, um DBS-Verbindungen zu interpretieren. Wenn das betreffende Skript PHP und das Datenbanksystem MySQL ist, benötigt das PHP-Skript sowohl korrekte Datenbankverbindungsparameter als auch eine genau definierte SQL-Anweisung. Beides kann gegen die MySQL-Serverinstanz geworfen werden, die sich dann mit der Abfrage befasst und die Ergebnismenge an den Webserver zurücksendet. Der Webserver macht dann das Gleiche wie immer, erstellt ein Markup und sendet es an den Browser des Clients zurück.
Das wäre eine vollständige Rundreise, und es ist wichtig, diese Interaktion zu verstehen, um eine eigenständige Webanwendung erfolgreich zu erstellen – und das ist unser Ziel.
Der WordPress-Ansatz
Alle oben genannten Komponenten sind bei einer WordPress-Installation noch auf bestimmte Weise vorhanden. Dennoch gibt es wichtige Unterschiede:
- Ein Content-Management-System wie WordPress dient dazu, Layout und Inhalt zu trennen.
- Du kannst Texte, Bilder und Videos hinzufügen, indem Du sie mit WordPress “Media Library” (über HTTPS anstelle von FTP/SSH) in WordPress hochlädst.
- Du kannst Theme-Dateien (PHP, JS, CSS) mit dem VI (oder auch mit manuellen Uploads) bearbeiten, kannst aber auch den WordPress-eigenen “Theme Editor” (unter “Darstellung”) verwenden.
- Du musst dir keine Gedanken darüber machen, wie PHP zum Generieren von HTML-Inhalten mithilfe der im CMS vorhandenen Inhalts- und Theme-Layout-Funktionen und Stildefinitionen verwenden wird.
Das folgende Schema zeigt die Architekturunterschiede von WordPress in Bezug auf eine eigenständige Website.

Bitte denke daran: Du musst die Grundprinzipien eines CMS oder zumindest eines WordPress-Themes verstehen, um fehlerhafte Dateien reparieren und dir bei deinem Blog-Projekt selbst helfen zu können. Aus diesem Grund führen dich die folgenden Kapitel durch alles, was Du mindestens über die Interaktion zwischen HTML, PHP und Datenbanken wissen musst.
Die nächsten Lektionen:
- Lektion 2: Grundlagen Relationaler Datenbank-Management-Systeme
- Lektion 3: Datenbank-Modellierung und -Strukturierung
- Lektion 4: VI-Editor in Unix
- Lektion 5: HTML-Grundlagen
- Lektion 6: HTML-Formular-Elemente
- Lektion 7: Ich lerne PHP: Grundlagen für Ausgabe, Kalkulation und Nutzung von Variablen
- Lektion 8: PHP-Schleifen und -Bedingungen
- Lektion 9: PHP-Funktionen richtig verwenden
- Lektion 10: PHP GET- und POST-Parameter
- Lektion 11: Wie baue ich eine Webseite — PHP-Navigationsskelett Schritt für Schritt
- Lektion 12: Verbindung von PHP zu MySQL herstellen
- Lektion 13: PHP Login-Skript-Tutorial
- Lektion 14: Dynamisches PHP-basiertes MySQL-Datenmanagement mit HTML-Output
In unserem SEO-Blog haben wir schon oft von sogenannten OnPage-Kriterien gesprochen, d.h. Faktoren, die Du auf der eigenen Webseite berücksichtigen solltest. Innerhalb dieser Kriterien spielen technische Anforderungen eine Rolle, welche oft von Content Management Systemen wie WordPress adressiert werden. Hingegen hatten wir im Rahmen des Web Audits bereits erwähnt, dass es Momente gibt, wenn Du die Dinge selbst in die Hand nehmen darfst. Die Verantwortung für den Quellcode ist stets bei dir, unabhängig von der Technologie die Du verwendest.
Kurzum, Du musst in der Lage sein, Dinge zu reparieren, wenn sie beschädigt sind. Dieses Tutorial gibt dir eine Schritt-für-Schritt-Anleitung in die Hand, um deine Webseite zu verstehen, besser zu konzipieren, kleine Dinge zu entwickeln und/oder beschädigten oder suboptimalen Code zu reparieren. Das Tutorial zeigt dir dies im Rahmen eines kleinen Standalone-Projektes: eine Datenbank-Anwendung, die in PHP geschrieben ist und mit einer MySQL-Datenbank spricht. Enthalten sind alle wesentlichen Schritte, die Du für eine minimale PHP-/MySQL-Datenbankanwendung benötigst.
Wir werden sowohl über Infrastruktur-Grundlagen als auch Datenbank-Konzepte sowie schließlich über Schritt-für-Schritt-Anleitungen für HTML- und PHP-Entwicklung sprechen. Bitte lies diese erste Seite so aufmerksam wie möglich bevor Du weiter liest.
Ein vollständiges PHP MySQL Tutorial
Dies ist dein Startpunkt. Du kannst jederzeit zu dieser Übersicht zurück kehren.
Los geht’s. Um ein verständliches Gesamtbild zu gewährleisten, haben wir dieses Tutorial didaktisch optimiert und chronologisch aufgebaut. Wir empfehlen es nacheinander durchzugehen.
- Lektion 1: Client- und Server-Infrastruktur: Datei-, Web- und Datenbank-Werkzeuge vs. WordPress
- Lektion 2: Grundlagen Relationaler Datenbank-Management-Systeme
- Lektion 3: Datenbank-Modellierung und -Strukturierung
- Lektion 4: VI-Editor in Unix
- Lektion 5: HTML-Grundlagen
- Lektion 6: HTML-Formular-Elemente
- Lektion 7: Ich lerne PHP: Grundlagen für Ausgabe, Kalkulation und Nutzung von Variablen
- Lektion 8: PHP-Schleifen und -Bedingungen
- Lektion 9: PHP-Funktionen richtig verwenden
- Lektion 10: PHP GET- und POST-Parameter
- Lektion 11: Wie baue ich eine Webseite — PHP-Navigationsskelett Schritt für Schritt
- Lektion 12: Verbindung von PHP zu MySQL herstellen
- Lektion 13: PHP Login-Skript-Tutorial
- Lektion 14: Dynamisches PHP-basiertes MySQL-Datenmanagement mit HTML-Output
Falls Du dich fragst, weshalb Du diese Lektionen verstehen solltest, kannst Du gern kurz weiter lesen.
Die Idee hinter moderner Web-Entwicklung
Warum solltest Du über PHP und MySQL überhaupt nachdenken? Nun, seit der Erfindung des Konzeptes “Web 2.0” wird der Besucher einer Webseite in die Erstellung der Inhalte der Webseite mit einbezogen. Beispielsweise kann ein Nutzer bei der Content-Erstellung mitwirken, indem er:
- einen Kommentar unterhalb eines Blog-Beitrags erstellt
- einen neuen Blog-Post oder eine Seite in WordPress erstellt
- einen Gästebuch-Eintrag auf einer privaten Webseite hinterlässt
- eine Antwort in einem Community-Forum schreibt
- den Text in einem Wiki ergänzt
- Bilder oder Videos in einem sozialen Netzwerk hoch lädt
- Dokumente mit Team-Mitglieder auf einer Kollaborationsplattform teilt
- Attribut-Werte in einer globalen Musik-Mediathek ergänzt
- Geo-Caching-Einträge ergänzt oder verändert
All diese Aktionen erfordern Daten-Verwaltungsfunktionen der jeweiligen Webseite. Eine Webseite gibt nicht länger nur einfachen hart kodierten HTML-Code aus. Webseiten des Web 2.0 erfordern dynamische Datenausgaben. Um dies zu gewährleisten findet Kommunikation zwischen einem Web- und einem Datenbankserver statt. Letzter hält die Daten vor und speichert neue Daten ab, während ersterer die Anfragen entgegen nimmt und die vom Datenbankserver erhaltenen Daten dynamisch aufbereitet und ausgibt.

Zwischen der Ausgabe strukturierter HTML-Daten und der Verwaltung von Daten via MySQL wird PHP als Skriptsprache verwendet. PHP wird verwendet, um verschiedene Algorithmen wie Schleifen und Sortierfunktionen auf die Daten der Datenbank anzuwenden, und schließlich wieder HTML-Code an den Browser des Besuchers zurück zu geben. Datenbanken wie MySQL halten die Daten vor, HTML formuliert visuelle Ausgaben, und PHP vermitteln zwischen beiden Welten.
Beispielsweise dient ein HTML-Formular als Möglichkeit zur Eingabe eines Gästebuch-Eintrages für den Nutzer. PHP liest diese Daten dann ein und formuliert einen Eintrag in die Datenbank. Das Datenbanksystem fügt die von PHP erhaltenen Daten ein und sendet ein OK. Die Webseite kann dann mittels PHP diese Daten erneut abrufen und via HTML das Gästebuch darstellen, welches alle Einträge enthält – inklusive dem zuletzt hinzu gefügten. PHP erfüllt dann nicht nur den Zweck der Abfrage der Datenbank, sondern generiert auch HTML-Code, den ein Browser verstehen kann.
Das kann alles sehr bedrohlich klingen. Ist es jedoch nicht. Alle zuvor erwähnten Konzepte werden in diesem Tutorial detailliert erläutert.
PHP- und Datenbank-Entwicklung für Blogger
Dieser Guide ist so strukturiert, dass Du ihn als Referenz für bestimmte Code-Schnipsel und Konzept-Ideen verwenden kannst – selbst wenn Du schon etwas Entwicklungserfahrung gesammelt hast. Dennoch erfordert dieses Tutorial keine Entwicklungserfahrung als Voraussetzung, um erfolgreich alle Lektionen zu bestehen. Jeder Blogger kann sämtliche hier erläuterten Inhalte verstehen. Tatsächlich wurde das vorliegende Material in ähnlicher Form bereits erfolgreich in verschiedenen Hochschulveranstaltungen eingesetzt – mit großem Erfolg und positivem Feedback.
Zu verstehen wie moderne Web-Technologien wie PHP und MySQL arbeiten ist essenziell um zu verstehen, wie Content Management Systeme wie WordPress arbeiten – und wie Du Themes und Plugins reparieren und optimieren kannst.
Sobald Du einen Überblick zu den jeweiligen Lektionen benötigst, kannst Du zu diesem Beitrag zurück kehren. Viel Spaß! 🙂
Schon oft sprachen wir in unserem SEO-Blog über die verschiedenen Ebenen, auf denen eine nachhaltige SEO-Methodik ansetzt, um dem eigenen Publikum (und damit auch Google) hochwertige Webseiten zu präsentieren. Neben rechtlichen Notwendigkeiten, einer sauberen inhaltlichen Struktur, Geschwindigkeit, Sicherheit und Backlinks wird ein Bereich sehr häufig vernachlässigt: die saubere technische Struktur der eigenen Webseite.
Was meint die technische Struktur?
Jede Webseite muss, damit sie von einem Browser dargestellt werden kann, HTML-Code an den Rechner des Besuchers ausliefern. Dieser HTML-Code unterliegt Konventionen, dem vom World Wide Web Consortium (W3C) definierten und fortwährend weiterentwickelten Web-Standard.

Weicht eine Webseite von diesen Konventionen ab, liegt es am Browser, diese Fehler zu erkennen und auszugleichen. Jeder Browser ist hier unterschiedlich weit entwickelt. So leistet Google’s Chrome hervorragende Arbeit darin, selbst grobe Verstöße am ausgelieferten HTML-Code zu optimieren, bevor die Webseite im Browser dargestellt wird. Firefox und Safari sind hier ähnlich stark aufgestellt, Microsoft’s Browser sind hierbei etwas hinterher.
Als SEO magst Du dich nun fragen, warum all dies für dich relevant sein sollte. Schließlich schreibst Du deine Webseite ja nicht als statisches HTML, sondern nutzt ein Content Management System wie WordPress, um dir deinen HTML-Code ausliefern zu lassen. Hierauf wollen wir nun weiter eingehen.
Die Fallstricke technischer Sauberkeit von WordPress-Webseiten
Wer ein Content Management System (CMS) wie WordPress für die Bereitstellung seiner Webseite einsetzt, wird häufig zur Ansicht verleitet, dass die Technik hierüber zu 100% abgedeckt ist. Schließlich ist es Aufgabe eines CMS für die Trennung aus Technik und Content zu sorgen, sodass man sich nur noch um den Content kümmern müsse.
Das ist so leider nicht korrekt. Dies begründet sich darüber, dass das CMS eine Webseite über die von Dritten bereitgestellten Themes bereitstellt. Der vom Betreiber erstellte Content wird in die Gussform dieser Themes gegeben, über verschiedene Plugins angereichert und optimiert, und auf diesem Weg über diverse, mehrschichtige PHP-Kontrollstrukturen und Datenbankzugriffe als Endresultat “Webseite” in Form des finalen HTML an den Browser des Besuchers zurückgegeben.
Das CMS selbst mag hierbei sauber arbeiten, und auch der eigene Content mag hochwertig sein. Doch zu sehr vertrauen SEOs weltweit auf die technische Integrität der von ihnen genutzten Themes und Plugins. Doch nicht umsonst gibt es nicht nur Updates für das CMS, sondern auch regelmäßige Updates für die genutzten Themes und Plugins.
Halte sowohl dein CMS, als auch deine Themes und Plugins auf dem neuesten Stand. Für Anpassungen am Theme nutze Child-Themes. Erstelle vor jedem Update ein Backup von Webspace und allen Datenbank-Inhalten.
Doch selbst wenn CMS, Themes und Plugins auf dem neuesten Stand sind, müssen sie nicht zwangsläufig optimal zusammen arbeiten. Folgende Probleme resultieren aus der Natur der Sache:
- Kompatiblitätsprobleme (Themes und Plugins untereinander, aber auch Themes und Plugins mit CMS- und/oder PHP- und MySQL-Versionen deines Web- und Datenbankservers)
- Versionskonflikte (meist zwischen unterschiedlich ausgereiften Themes und Plugins aber auch zwischen Themes/Plugins und CMS-Version)
- Neu auftretene Bugs bei sämtlichen Weiterentwicklungen von CMS, Themes, Plugins, PHP- und MySQL-Releases
All dies sorgt für die Konsequenz, dass ein jedes WordPress-Projekt zu einem bestimmten Zeitpunkt starke Defizite in der technischen Struktur aufweisen kann. Dies mündet in die Notwendigkeit des wiederholten Audits eines jeden Webseiten-Projektes.
Prüfe deine Webseite regelmäßig mit einem Web Auditor, da mit jedem Update an deiner Webseite Veränderungen an der technischen Struktur entstehen können.
Was hat ein Web Audit zum Ziel?
Ein Audit ist ein Werkzeug aus dem Qualitätsmanagement. Jedes Audit prüft vorhandene Technik und/oder Prozesse gegen zuvor definierte Richtlinien und Anforderungen.
Bei einem Web Audit werden die Anforderungen nicht vom SEO oder von Google, sondern vom World Wide Web Consortium (W3C) definiert. Die Erfüllung dieser Richtlinien wird von Google als Qualitätsmerkmal der vom SEO bereitgestellten Webseite geprüft und fließt in die Ranking-Vergabe mit ein. Technische Sauberkeit ist somit ein direktes Kriterium für bessere Platzierungen einer Webseite auf Google.
Ein Web-Audit prüft insbesondere folgende allgemeinen Faktoren:
- Doc-Type der Webseite
- Inhalte der robots.txt
- Existenz einer Sitemap
Weiterhin können SEO-relevante Inhalte geprüft werden:
- Titel einer Unterseite
- Länge des Titels
- Meta-Description der Unterseite
- Länge der Description
Auch können Anforderungen der Mobiloptimierung und der Ergonomie geprüft werden, welche ebenfalls Einfluss auf die SEO-Optimierung haben können, darunter:
- Anzahl der Bilder ohne ALT-Attribut
- Existenz einer Viewport-Angabe
Ferner gibt es sicherheitsrelevante Anforderungen, welche im modernen Web ebenfalls erfüllt sein sollten, darunter beispielsweise:
- SSL-Verschlüsselung
- Existenz einer Content Security Policy
- Existenz einer Referrer Policy
Schließlich können Whois-Daten der eigenen Webseite und die Daten des W3C-Validators direkt in das Audit übernommen werden.
SERPBOT Web Auditor
SERPBOT adressiert die Prüfung all dieser Anforderungen im SERPBOT Web Auditor, den Du als registrierter Nutzer kostenfrei nutzen kannst. Zusätzliche Prüfungen mit Mehrwert, die auf unserer Seite mit Kosten verbunden sind, stehen allen PRO-Nutzern zur Verfügung.
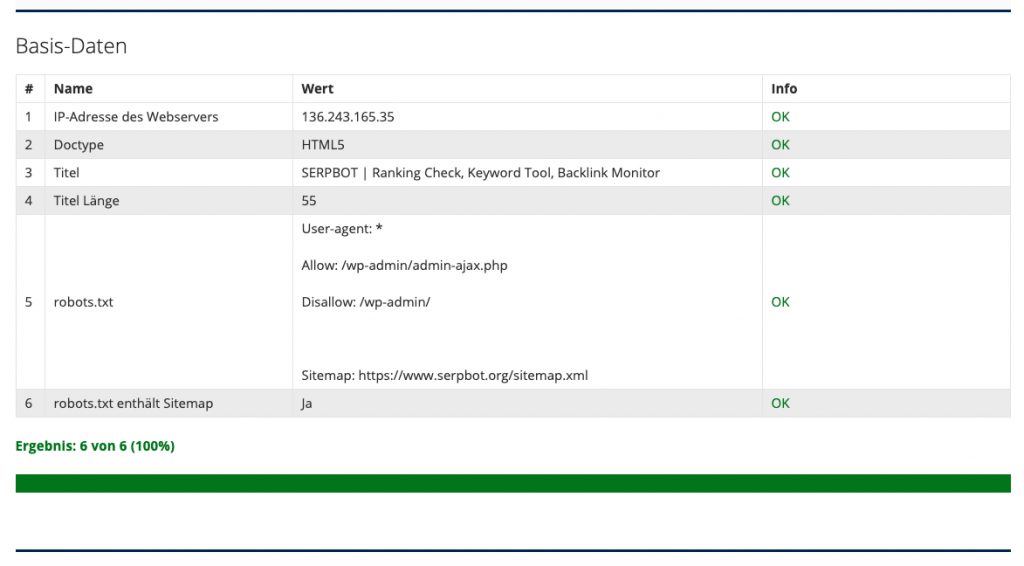
Ausschnitt aus SERPBOT Web-Auditor-Modul
Das Fazit Web Audit
Eine jede moderne Webseite wird mittels CMS ausgeliefert. Hier wirken das CMS und die darin verwendeten Themes und Plugins zusammen. Jede dieser Komponenten hat zu unterschiedlichen Zeitpunkten verschiedene Versionen, die unterschiedlich gut miteinander zusammenwirken.
Potenziert wird dies über neue PHP- und MySQL-Versionen, die neue Funktionen bereitstellen und alte abschaffen, sodass für jeden CMS-, Theme- und Plugin-Hersteller ein regelrechtes Wetttreiben dahingehend besteht, die Webseite funktionsfähig zu halten. Hierbei entstehen nicht nur technische Herausforderungen, sondern auch menschliche Fehler, die in wieder neuen Versionen ausgeglichen werden müssen.
Dieses hoch komplexe Zusammenspiel aus technischen Veränderungen und dynamisch generierten Webseiten mündet in eine direkte Notwendigkeit: dem regelmäßigen Audit der eigenen Webseite — einem Web Audit. SERPBOT bietet mit dem Web Auditor daher einen starken verbündeten für deine Web-Projekte.